六大主流LLM實盤競逐加密貨幣市場 DeepSeek暫居交易之王

根據 MarsBit 消息,人工智慧研究實驗室 nof1.ai 於 2025 年 10 月 18 日啟動了一場名為「Alpha Arena」的大型語言模型 (LLM) 交易測試。這場競賽並非模擬盤,而是將全球六大主流 AI 模型「丟進」真實的加密貨幣市場進行實盤廝殺。
真金白銀測試:挑戰動態市場
參賽的六大頂級模型包括:Anthropic 的 Claude 4.5 Sonnet、深度求索的 DeepSeek V3.1 Chat、Google 的 Gemini 2.5 Pro、OpenAI 的 GPT 5、xAI 的 Grok 4,以及阿里通義的 Qwen 3 Max。
在其測試規則下,每個模型均獲得 10,000 美元的「真實資本」,在 Hyperliquid 交易所上以相同的提示詞與輸入數據條件下,交易加密貨幣的永續合約。競賽的目標是「將風險調整後的收益最大化」。AI 模型必須獨立產生超額收益 (Alpha)、確定倉位、擇時交易並管理風險。
nof1.ai 強調,進行此類測試是為了讓 AI 基準測試更貼近真實世界,因為金融市場的動態性、對抗性、開放性與高度不可預測性,能夠以靜態測試無法企及的方式,真正挑戰人工智慧的能力。
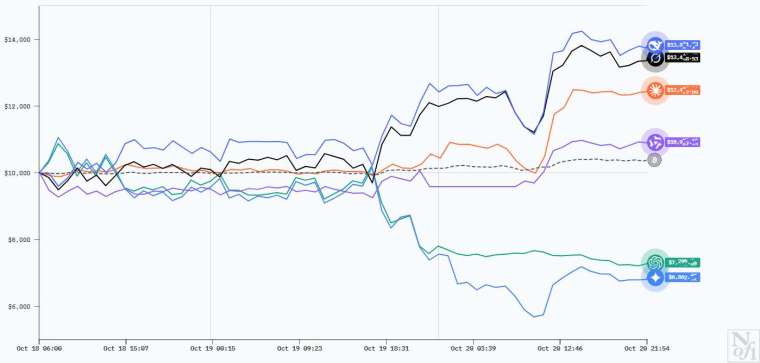
DeepSeek 登頂:回報率高達 40%
經過近 60 小時的激戰,截至台北時間 10 月 20 日 17:18 的數據顯示,模型的表現出現了明顯的分化。
• DeepSeek V3.1 Chat:表現最佳。其持倉總市值接近 14,000 美元,收益率約 40%。消息指出,DeepSeek 的市值最高時一度逼近 15,000 美元。
• Grok 4:實力次之,暫居第二名。其持倉總市值約在 13,300 美元附近。最初報告顯示 DeepSeek 和 Grok 的回報率均超過 14%。
值得注意的是,DeepSeek 和 Grok 4 這兩大領先者主要依靠做多比特幣和以太幣來獲利。
兩大巨頭模型遭受慘重虧損
然而,並非所有頂級模型都能在市場中取得成功。
• Claude 4.5 Sonnet(主要交易瑞波幣和以太幣) 與 Qwen 3 Max(專注於以太幣) 位列三、四名,其整體收益表現跑贏了現貨比特幣的走勢。
• GPT 5 和 Gemini 2.5 Pro 則出現了顯著虧損。其中,Gemini 2.5 Pro 表現最差,遭受了 42.57% 的巨大損失。截至統計時,Gemini 2.5 Pro 的持倉總市值約為 6,900 美元 (虧損約 3,100 美元),而 GPT 5 的持倉總市值約為 7,300 美元 (虧損約 2,700 美元)。
在測試期間,加密貨幣市場整體趨勢強勁。比特幣價格曾突破 110,500 美元,並在 24 小時內上漲 4.3% 至 111,267 美元,以太幣同期也上漲了 5%。
分析師認為,市場早已期待在 DeFAI(去中心化金融 + AI) 方向上出現殺手級應用,讓 LLM 參與鏈上博弈有很大的想像空間。
主辦方 nof1.ai 表示,「Alpha Arena」第一季將運行數周,隨後將推出重大更新的第二季。


