〈研之有物〉打造「聊」癒系機器人!看圖說故事 AI也略懂略懂

AI 如何看圖說故事?
看圖說故事對人類來說,是輕鬆好玩的事,但對 AI 來說,卻是巨大挑戰,因為這代表 AI 必須看出圖中有哪些物件、理解圖片意義、能夠生成文句,還要看懂圖片間的因果邏輯。在中研院資訊科學研究所古倫維副研究員的努力下, AI 看圖說故事的能力有了很大的進展。她的模型有什麼獨特之處呢?跟著研之有物一起來瞧瞧!
俗話說得好:「發文不附圖,此風不可長。」不論你發的是爆卦文、閒聊文還是業配文,有圖更容易晉身流量熱文。不過近年來,社群網站發文的風向漸漸有了改變,從「發文附圖」轉變成「發圖附文」,我們總是先來一張照片,再配上相應的描述文字。接下來,我們的發文習慣還會怎麼改變?
或許,未來你拍下一張照片上傳社群網站,電腦就會自動「看圖說故事」,為你的照片腦補一段說明文字,節省你的思考時間。
讓電腦學會「看圖說故事」的伎倆,正是中研院資訊科學研究所的古倫維副研究員正在鑽研的主題之一。她的主要研究領域是人工智慧( AI )的自然語言處理,在因緣際會下,接觸到一個 AI 看圖說故事的競賽: Visual Storytelling ( VIST ),開啟了她對 AI 看圖說故事的興趣。

電腦如何學會「看圖說故事」?目前學界使用「機器學習」,簡單來說,就是讓電腦從大量的圖文搭配組合,從中學習看到怎樣的圖片,應該說出怎樣的故事。中研院資訊所古倫維副研究員說:「其實一開始我們做得並不特別好。我們跟其他參加競賽的人一樣,用機器學習的方法,把圖和對應的文字丟進電腦,讓機器自己學習最佳的圖文搭配。然而機器學習幾乎是軍備競賽了!誰的電腦計算能力更強,得到的模型更複雜,生成的文字就會更好。」
先選角、打草稿,再寫故事
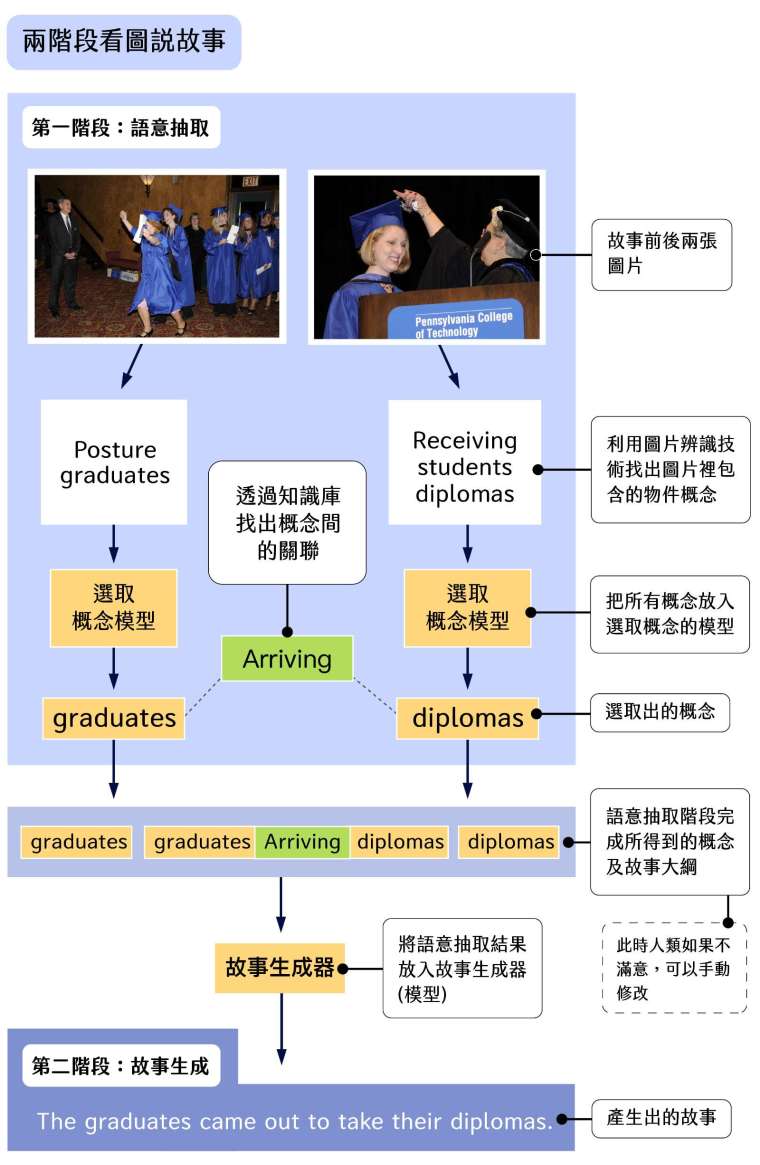
在軍備競爭不足的情況下,古倫維決定採取不同的策略:「既然完全由 AI 看圖說故事的效果不夠好,能不能在故事生成的過程中,有一個人類可以介入改善的步驟。」所以她把原來的做法分成了兩個階段,先從圖片抽取語意,接著再生成文字故事。
語意抽取,是指先從個別圖片中選出用來說故事的概念(如同電影選角),用知識庫找出概念之間的關係,建立圖片的關聯,再為這些圖片擬定最好的草稿(如同電影故事大綱)。
重點來了!在「選角」階段, AI 會先以機器學習的結果,找出最適合說故事的「角色組合」,尤其是面對連續圖片。這就好比張曼玉、梁朝偉、成龍三個演員,前兩個主要演愛情片,第三個以武打戲為主,如果第一張照片選了張曼玉,第二張照片應該選梁朝偉,生成的故事會比較好看。
但目前 AI 選角部分還不夠靈光,有時仍會發生如「張曼玉配成龍」的選角名單。古倫維的兩階段設計讓人類可在「選角」階段介入修改。實際例子如:圖片中有小男孩、天空、腳踏車三個概念。AI 從上圖抽取出的概念可能是「小男孩」、「天空」,最後生成的故事可能是「一個小男孩在天空下」…… 滿無聊的。但人類可以把「天空」改成「腳踏車」,機器最後就可能生成「一個小男孩騎著腳踏車。」嗯,是不是比較有故事性了?
最後,人類再將修改後的選角和故事大綱,交給 AI 產生整個故事。這種「先選角、打草稿,再說故事」的方式,最後產生的故事比較不會無聊或是不合理,更接近人類說出的故事。
知識庫,AI 想像力的補充包
為了增加 AI 的想像力,古倫維也在模型中納入「知識庫」,幫 AI 增加故事的知識。例如圖片中有人與馬,如果沒有知識庫,AI 可能只能生成「有一個人與一匹馬」這種平淡的句子。但知識庫可以補充人與馬關聯的知識,包括人可以騎馬、養馬等等,讓 AI 有機會說出「有一個人騎著自己養的馬」比較具故事性的句子。「當然 AI 也可能從大量的故事中以機器學習取得『很多人都會騎馬、養馬』的知識。但知識庫的最大功用,就是直接提供這個知識給 AI ,縮短學習歷程。」 古倫維解釋。
更重要的是,知識庫讓 AI 更容易解讀出圖片之間的關聯。如 VIST 競賽的題目就是包含了五張圖片的圖組,在知識庫的協助下, AI 比較容易找出各別圖片的概念之間的關聯,說出的故事會比較連貫,具有因果關係。
AI 是完全沒有想像力的,但若透過知識庫給它知識,這些知識在故事中呈現出來的,就像是 AI 的想像力。
巧妙切開「語意抽取」與「生成文本」
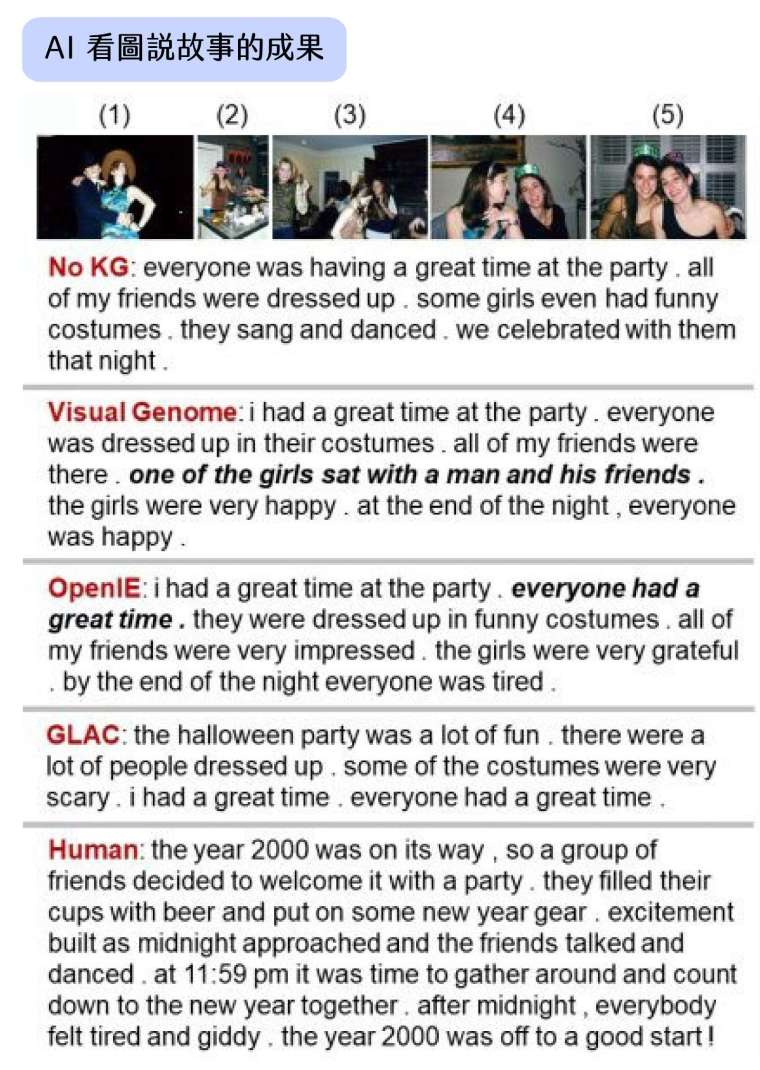
兩階段生成故事的方法還有一個優點,就是可善用大量的「圖片辨識」與「故事文本」資料庫,避開「圖文搭配」資料的缺乏。
現今的「圖片辨識」技術和資料庫非常成熟,可以精準的從圖片中抽取出各式各樣的概念。另一方面,說故事是人類從古至今不斷從事的活動,留下了大量的「故事文本」。相較之下,看圖說故事的「圖文搭配」資料量卻相當少,需要有人刻意去蒐集圖組、撰寫文字,古倫維說:「這種圖文搭配的資料必須人工建立,能有一萬組就很厲害了,但這個數量對於機器學習來說卻是遠遠不夠的。」
古倫維則把生成故事的過程拆成「語意抽取」與「生成文本」兩個階段,第一階段可利用精熟的圖片辨識技術和資料庫,抽取故事概念;第二階段再運用故事文本資料庫,讓機器學習如何將第一階段抽取(並由人類修改過)的概念,組合成漂亮的故事,巧妙避開了「圖文搭配」資料不足的難題。
把「語意抽取」與「生成文本」切開的話,兩個階段都可以利用幾千萬筆的既有資料,供機器學習。
腦補,讓機器更有溫度
說了半天,但 AI 會看圖說故事,到底能幹嘛?難道只是幫貼圖寫寫圖說?以研究的層面來說,如果 AI 能看圖說故事,代表 AI 在理解圖片、文字分析及因果邏輯等方面,都達到一定的水準,代表 AI 語言能力更加接近人類。在實際應用上, 可以為圖文創作者提供故事草稿,或是對於常常需要撰寫廣告文案、出差報告的人,能夠很快從圖像生成文本,人類只要略做修改潤飾即可 (小職員計畫通!)。
但更重要的是,機器人也能因此更有溫度!古倫維與臺大人工智慧與機器人研究中心的傅立成教授合作,希望透過 AI 看圖說故事的技術,讓居家照護機器人更有「人味」,會主動關懷人類。因為居家照護機器人在家中「看見」的一切,其實就是一張張的圖, AI 可以透過這些「圖」形成可能的故事,再轉化為暖心的問句。
想像一下,未來居家照護機器人看見老人家在廚房,故事劇情可能是「他要煮飯」,於是問出:「今晚想吃什麼?需要幫忙嗎?」當老人拿出相簿緬懷過去,AI 也能從舊照片解讀可能故事,轉化成聊天的問句:「照片中的這個人是誰啊?你們去哪裡玩?」還能變身孩子最愛的說故事姊姊!AI 可能從儲存的繪本資料庫中,隨機抽出不同圖畫重新組合,說出全新的故事。
會看圖說故事的 AI ,可以從眼前的情景連結到事件或情感,就像人類的腦補一般,而這些腦補就是故事。

如此一來,居家照護機器人不再只是被動的處理人類需求,相反的,「說故事的能力賦予了 AI 機器人找話題的功能。」古倫維笑著解釋,機器人從此不再詞窮,可以主動關心人類,與人類互動聊天,讓機器人變得溫暖許多。看來 AI 看圖說故事,不只是寫寫圖說、幫忙解決麻煩的出差報告,在不遠的未來,更是拉近我們與機器人距離的關鍵所在呢。
原文連結:打造「聊」癒系機器人!看圖說故事,AI 也略懂略懂
延伸閱讀:


